Machine Learning on 2nd Generation Intel® Xeon Phi™ Processors: Image Captioning with NeuralTalk2, Torch
In this case study, we describe a proof-of-concept implementation of a highly optimized machine learning application for Intel Architecture. Our results demonstrate the capabilities of Intel Architecture, particularly the 2nd generation Intel Xeon Phi processors (formerly codenamed Knights Landing), in the machine learning domain.
Download as PDF: ![]() Colfax-NeuralTalk2-Summary.pdf (814 KB) or read online below.
Colfax-NeuralTalk2-Summary.pdf (814 KB) or read online below.
Code: see our branch of NeuralTalk2 for instructions on reproducing our results (in Readme.md). It uses our optimized branch of Torch to run efficiently on Intel architecture.
See also: colfaxresearch.com/get-ready-for-intel-knights-landing-3-papers/

1. Case Study
It is common in the machine learning (ML) domain to see applications implemented with the use of frameworks and libraries such as Torch, Caffe, TensorFlow, and similar. This approach allows the computer scientist to focus on the learning algorithm, leaving the details of performance optimization to the framework. Similarly, the ML frameworks usually rely on a third-party library such as Atlas, CuBLAS, OpenBLAS or Intel MKL to implement basic linear algebra subroutines (BLAS), particularly general matrix-matrix multiplications (GEMMs) which are an essential building block of convolutional neural networks and other ML methods. This layered approach allows to adapt ML applications to different underlying computer architectures with relative ease, by optimizing the middleware (the ML framework), which may include linking it to the appropriate BLAS library.
Because the recently released 2nd generation Intel Xeon Phi processors (formerly codenamed Knights Landing, or KNL), have high performance capabilities in BLAS, they are well-suited as computing platforms for ML applications. Ideally, computer scientists should not need to modify their code at all, and only the framework must be updated to extract the performance capabilities out of the new processors. In this study we performed an experiment to determine what it takes to adapt an application based on a neural network algorithm to run on an Intel Xeon Phi processor.
The starting point for this study is an open-source project called NeuralTalk2 developed by Andrej Karpathy and Fei-Fei Li, Stanford University. This application uses machine learning to analyze real-life photographs of complex scenes and produce a verbal description of the objects in the scene and relationships between them (e.g., “a cat is sitting on a couch”, “woman is holding a cell phone in her hand”, “a horse-drawn carriage is moving through a field”, etc.)
NeuralTalk2 is a recurrent neural network for image captioning. It uses a VGG net for the convolutional neural network, and a long short-term memory (LSTM) network composed of standard input, forget, and output gates. NeuralTalk2 is written in Lua, and is using the machine learning framework Torch.
Out-of-box performance of NeuralTalk2 on Intel architecture is sub-optimal due to inefficient usage of Intel Architecture capabilities by the Torch library. Our goal for this study was to demonstrate that it is possible to accelerate machine learning applications that rely on middleware, such as Torch, by optimizing the middleware and largely leaving the original code (e.g., in the Lua language) without modification. This means that developers and researchers can continue using existing machine learning applications and benefit from the Intel architecture by simply updating their middleware.
We focused on the forward pass (i.e., inference) of the network, as a trained model was distributed with the network. The metric for performance we used was the throughput for the network, measured as the average time of captioning an image in a batch of images.
2. Optimization Work
Our contributions to the performance optimization in Torch and NeuralTalk2 are summarized below.
- Rebuilt the Torch libraries with the Intel C Compiler, linking the BLAS and LAPACK functions in Torch to the Intel MKL library.
- Performed code modernization in the Torch:
- Improved various layers of VGG net with batch GEMMs, loop collapse, vectorization and thread parallelism.
- Improved the LSTM network by vectorizing loops in the sigmoid and tanh functions and using optimized GEMM in the fully-connected layer.
- Incorporated algorithmic changes in the code of NeuralTalk2 in an architecture-oblivious way (e.g., replaced array sorting with top-k search algorithm to locate the top 2 elements in an array).
- Improved the parallel strategy for increased throughput by running several multi-threaded instances of NeuralTalk2, pinning the processes to the respective processor cores.
- Took advantage of the high-bandwidth memory (HBM) based on the MCDRAM technology by using it in the cache mode.
3. Preliminary Results
Through our optimization work, we attained performance improvement by a factor over 50x on 2nd generation Intel Xeon Phi Processors. Optimized code also experiences performance gains in excess of 25x on general-purpose Intel Xeon processors of the Broadwell architecture. Performance results are summarized in the plot below.
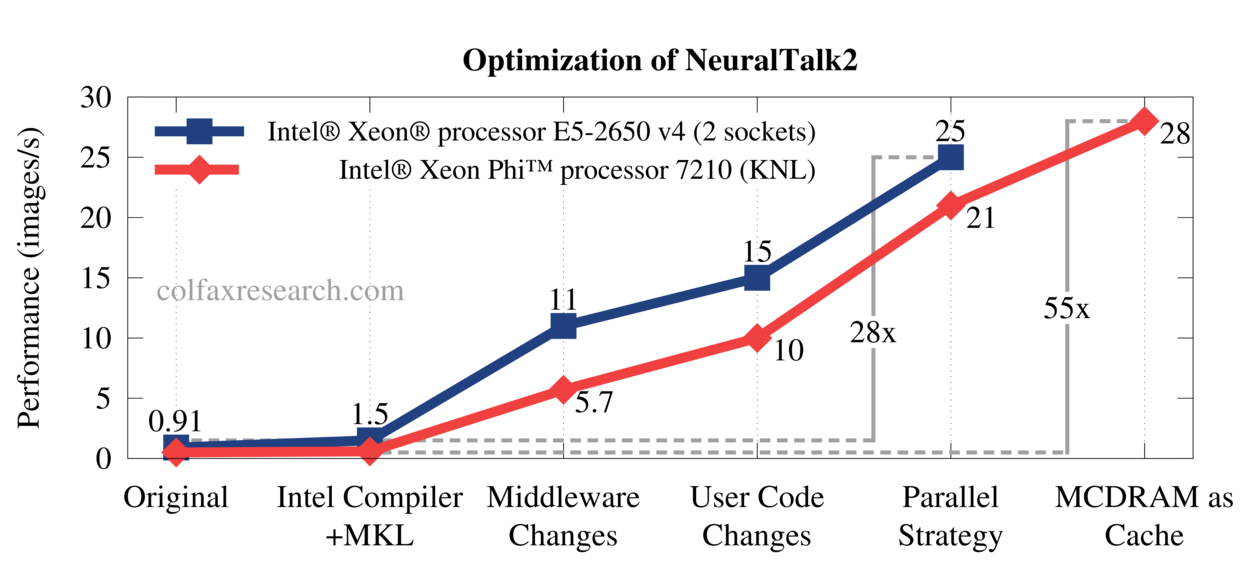
Figure 1: Significant performance gains through code modernization.
4. Conclusion
Code modernization allowed us to achieve significant performance improvement in our case study of a machine learning application based on neural networks. This applies to the new Intel Xeon Phi processors as well as to well-established general-purpose CPUs. Importantly, the same exact code in Lua and in C is used on both platforms (with the exception of compiler arguments).
We believe that further performance optimization is possible through the use of better GEMM algorithms for the many-core architecture. This, according to our private communications, is work in progress in the Intel MKL team.
Additionally, structuring the application (in this case, NeuralTalk2) with parallelism in mind may help to take advantage of multiple CPU cores in a better way than running multiple processes. This, however, is beyond the scope of our work.
In earlier work (to be published elsewhere), we have demonstrated the possibility of using Torch in conjunction with the Message Passing Interface (MPI) framework, thus scaling the applications across a cluster of Intel Xeon Phi processors for improved throughput. Given the embarrassingly parallel nature (i.e., low communication rate) of the forward pass stage of neural networks, it is natural to expect linear scalability of the application throughput with the number of compute nodes.
This publication accompanies a live demonstration of the NeuralTalk2 application on a 2nd generation Intel Xeon Phi processor at the 2016 ISC High Performance conference.
Great job on optimization job on IA!
Our team is in charge of Torch optimization on Xeon/Xeon Phi, currently focusing on ImageNet topologies.
We are close to open source Intel-Torch on GitHub soon.
I think we can exchange ideas of providing the best performance for Torch on IA.
Could you please inform me of where can I get the code?
looking forward for your reply.
Thanks! We will post the code on this page once our team gets re-united after the ISC in Frankfurt. If you are at the conference, make sure to meet up with lead author, Bonan, who is showing the demo at the Intel booth.
Any ETA on the Intel-Torch project?
Also I am building deep learning workstation for Torch, and will love to hear your insights into Intel Phi vs cuDNN performance.
Intel will have to speak for themselves regarding Intel’s Torch, but we have recently published our branch of optimized Torch here: https://github.com/ColfaxResearch/torch7 It contains optimization work that made it possible to achieve the quoted speedup in NeuralTalk2. If you want an application-driven benchmark of Intel Xeon Phi versus a GPU, you can use NeuralTalk2 – it is capable of running on a GPU.
Thank you – checking the code now.
Intel Torch is hosted here: https://github.com/xhzhao/Intel-Torch
Great job!
But, I didn’t see Phi is much better than Xeon in your result.
There should be something in Torch that could not work well on Xeon Phi (for example, external libraries).
Frameworks and libraries that designed for Xeon (heavy core) may be not suitable for Xeon Phi (Lightweight core). I do think that a re-design framework is a better choice.
Anyway, this is a good try!
We agree, the Torch framework was not performing well on Xeon Phi, and this is why we invested the effort into optimizing it. Ideally, people should not re-write their code, only upgrade the framework. Our results are labelled “preliminary” because we see that there is potential for getting more out of the Xeon Phi than a comparable (by $ and W) Xeon. Bottom line, this story is more about performance optimization to get performance out of any platform than about Xeon Phi versus Xeon.
Does the choice of software tools make a difference? For example, did you try some other C compiler and some other math library? Does performance matter that way?
Yes, it does make some performance difference. Although a lot of the performance optimizations that we have applied are generic, Intel Compilers and non-Intel compilers do have performance differences. And OpenBLAS does seem to perform slightly worse than MKL.
We have not yet done a thorough test of the performance doifferences, but it can account for a factor of a few in some situations.
We will be publishing a more thorough version of this study (this page is a summary), in which we will try to also discuss performance differences between GCC/ICC and OpenBLAS/MKL.