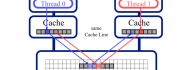
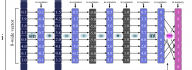
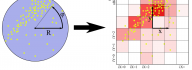
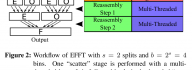
An optimization approach for agent-based computational models of biological development
Pablo Gonzalez-de-Aledoa, Andrey Vladimirovd, Marco Mancab, Jerry Baughc, Ryo Asaid, Marcus Kaisere,f, Roman Bauerf,e a Software Performance Optimization Group, Imperial College London, London, United Kingdom b CERN Openlab, IT Department, CERN, Switzerland c Intel Corporation, USA d Colfax International, USA e Interdisciplinary Computing and Complex BioSystems Research Group, School of Computing, Newcastle University, Newcastle upon Tyne, United Kingdom f Institute of Neuroscience, Newcastle University, Newcastle upon Tyne, United Kingdom A paper led by Pablo Gonzales-de-Aledo (Imperial College London) with contributions from his colleagues from CERN, Intel, Colfax and Newcastle University was published in the journal Advances in Engineering Software. This is a case study on performance optimization in a biological simulation code. The code presents a highly parallel implementation of a computer simulation that involves millions of agents interacting in a 3D environment. The paper explains the general approach to transforming a sequential code to run on modern, highly [...]