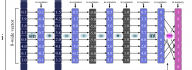
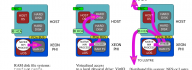
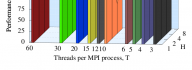
Are You Realizing the Payoff of Parallel Processing?
My contributed article has just been published at Intel Communities. …as Intel processor architectures evolve, you get performance boosts in some areas without doing anything with your code. For instance, such architectural improvements as bigger caches, instruction pipelining, smarter branch prediction, and prefetching improve performance of some applications without any changes in the code. However, parallelism is different. To realize the full potential of the capabilities of multiple cores and vectors, you have to make your application aware of parallelism. That is what code modernization is about: it is the process of adapting applications to new hardware capabilities, especially parallelism on multiple levels. … Once you have a robust version of code, you are basically future-ready. You shouldn’t have to make major modifications to take advantage of new generations of the Intel architecture. Just like in the past, when computing applications could “ride the wave” of increasing clock frequencies, your modernized code will be able to automatically take [...]