A Performance-Based Comparison of C/C++ Compilers
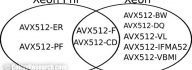
This paper reports a performance-based comparison of six state-of-the-art C/C++ compilers: AOCC, Clang, G++, Intel C++ compiler, PGC++, and Zapcc. We measure two aspects of the compilers’ performance: The speed of compiled C/C++ code parallelized with OpenMP 4.x directives for multi-threading and vectorization. The compilation time for large projects with heavy C++ templating. In addition to measuring the performance, we interpret the results by examining the assembly instructions produced by each compiler. The tests are performed on an Intel Xeon Platinum processor featuring the Skylake architecture with AVX-512 vector instructions. Colfax_Compiler_Comparison.pdf (562 KB) Table of Contents 1. The Importance of a Good Compiler 2. Testing Methodology 2.1. Meet the Compilers 2.2. Target Architecture 2.3. Computational Kernels 2.4. Compilation Time 2.5. Test Details 2.6. Test Platform 2.7. Code Analysis 3. Results 3.1. Performance of Compiled Code 3.2. Compilation Speed 4. Summary Appendix A. LU Decomposition Appendix B. Jacobi Solver Appendix C. Structure Function Appendix [...]