Squeezing More Instructions per Cycle out of the Intel Sandy Bridge CPU Pipeline
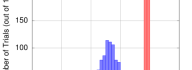
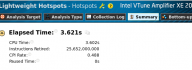
Parallelism in modern CPU architectures is supported at hardware level by multiple cores, vector registers, and pipelines. While the utilization of the former two is a shared responsibility of the programmer and the compiler, pipelining is handled completely by the processor. It is, however, useful for the developer to know what types of workloads optimize pipeline utilization. This paper shows one example where a specific workload improves the number of instructions executed per clock cycle, boosting arithmetic performance. This workload is comprised of two independent data processing tasks, one performing the AVX addition instruction and the other — the AVX multiplication instruction. Even though these tasks are executed sequentially on one core, alternating additions and multiplications in the code allows the CPU to complete the task 40% faster than when a sequence of additions is followed by a sequence of multiplications. Such workloads are common in linear algebraic applications. Examples in the paper illustrate how improved performance can be achieved in portable C code [...]