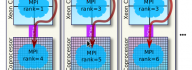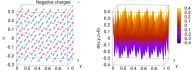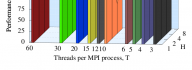
Cluster-Level Tuning of a Shallow Water Equation Solver on the Intel MIC Architecture
The paper demonstrates the optimization of the execution environment of a hybrid OpenMP+MPI computational fluid dynamics code (shallow water equation solver) on a cluster enabled with Intel Xeon Phi coprocessors. The discussion includes: Controlling the number and affinity of OpenMP threads to optimize access to memory bandwidth; Tuning the inter-operation of OpenMP and MPI to partition the problem for better data locality; Ordering the MPI ranks in a way that directs some of the traffic into faster communication channels; Using efficient peer-to-peer communication between Xeon Phi coprocessors based on the InfiniBand fabric. With tuning, the application has 90% percent efficiency of parallel scaling up to 8 Intel Xeon Phi coprocessors in 2 compute nodes. For larger problems, scalability is even better, because of the greater computation to communication ratio. However, problems of that size do not fit in the memory of one coprocessor. The performance of the solver on one Intel Xeon Phi coprocessor 7120P exceeds the performance on a dual-socket Intel Xeon E5-2697 v2 CPU by a [...]